Blog
Engineering
Evaluating AI Agents in Security Operations
We benchmarked frontier AI models on realistic security operations (SecOps) tasks using Cotool’s agent harness and the Splunk BOTSv3 dataset. GPT-5 achieved the highest accuracy (63%), while Claude Haiku-4.5 completed tasks the fastest with strong accuracy. GPT-5 variants dominated the performance-cost frontier. These results provide practical guidance for model selection in enterprise SecOps automation.

Eddie Conk
CPO & Head of AI
Nov 17, 2025

Find the latest results for this benchmark at our interactive research site: https://research.cotool.ai/benchmarks/botsv3
NOTE: We updated results to this eval in a new blog post in December 2025
“You can’t improve what you don’t measure” - often attributed to Peter Drucker
TL;DR: We benchmarked frontier AI models on realistic security operations (SecOps) tasks using Cotool’s agent harness and the Splunk BOTSv3 dataset. GPT-5 achieved the highest accuracy (63%), while Claude Haiku-4.5 completed tasks the fastest with strong accuracy. GPT-5 variants dominated the performance-cost frontier. These results provide practical guidance for model selection in enterprise SecOps automation.
Why evaluate
Evaluations (evals) are one of the most important parts of any agentic AI system. Their purpose is to quantify how well a system performs on a specific task or set of tasks. Evals help you answer questions like “How good is my agent at my task?” or “Will this new tool make my agent better or worse at my task?”
The Problem
Evals are hard to build. Agents operate over multiple steps, often along non-deterministic trajectories with dynamic tools and external systems. Verifying correctness alone can be challenging, especially when you want to evaluate across multiple criteria like accuracy, cost, and latency. Even with carefully labeled data, building a realistic environment that simulates the task can be difficult.
Labeling production runs helps you measure historical performance, but it’s not enough. The real goal is to have a sandbox environment where you can run an agent on a known input and extract a metric that approximates real-world performance (much like unit tests in software engineering). Even better, an environment like this opens the door to more sophisticated optimization techniques on your agent, such as prompt optimization or reinforcement learning (RL).
Cotool already provides security teams with a purpose-built agent harness to build practically any security operations agent they can imagine. This harness includes an in-house connector platform to all the tools in your security stack, supporting a variety of SIEMs (including Splunk, as we leverage in this eval) among many other integrations. It’s with this harness we run the eval.
The Eval
For this first benchmark, we reproduced the Splunk BOTSv3 blue team Capture the Flag (CTF) environment. BOTSv3 comprises over 2.7M logs (spanning over 13 months) and 59 Question and Answer pairs that test scenarios such as investigating cloud-based attacks (AWS, Azure) and simulated APT intrusions. Splunk is a popular Security Information and Event Management (SIEM), often used for log aggregation and analytics. For the eval environment, we built a Splunk Enterprise instance and indexed the full BOTSv3 dataset. We then gave a Cotool Agent access to a few simple Splunk tools: search, listDatasets, and describeSourceType. These allowed the agent to query the Splunk instance, list available datasets, and describe the source type to answer each question.
We provide a few examples of the question and answer pairs below:
Q: What external client IP address is able to initiate successful logins to Frothly using an expired user account?
A: 199.66.91.253
Q: Bud accidentally makes an S3 bucket publicly accessible. What is the event ID of the API call that enabled public access? Answer guidance: Include any special characters/punctuation.
A: ab45689d-69cd-41e7-8705-5350402cf7ac
We go into more detail about nuances in our methodology below, but for now let’s dive into the results.
Results
Accuracy:
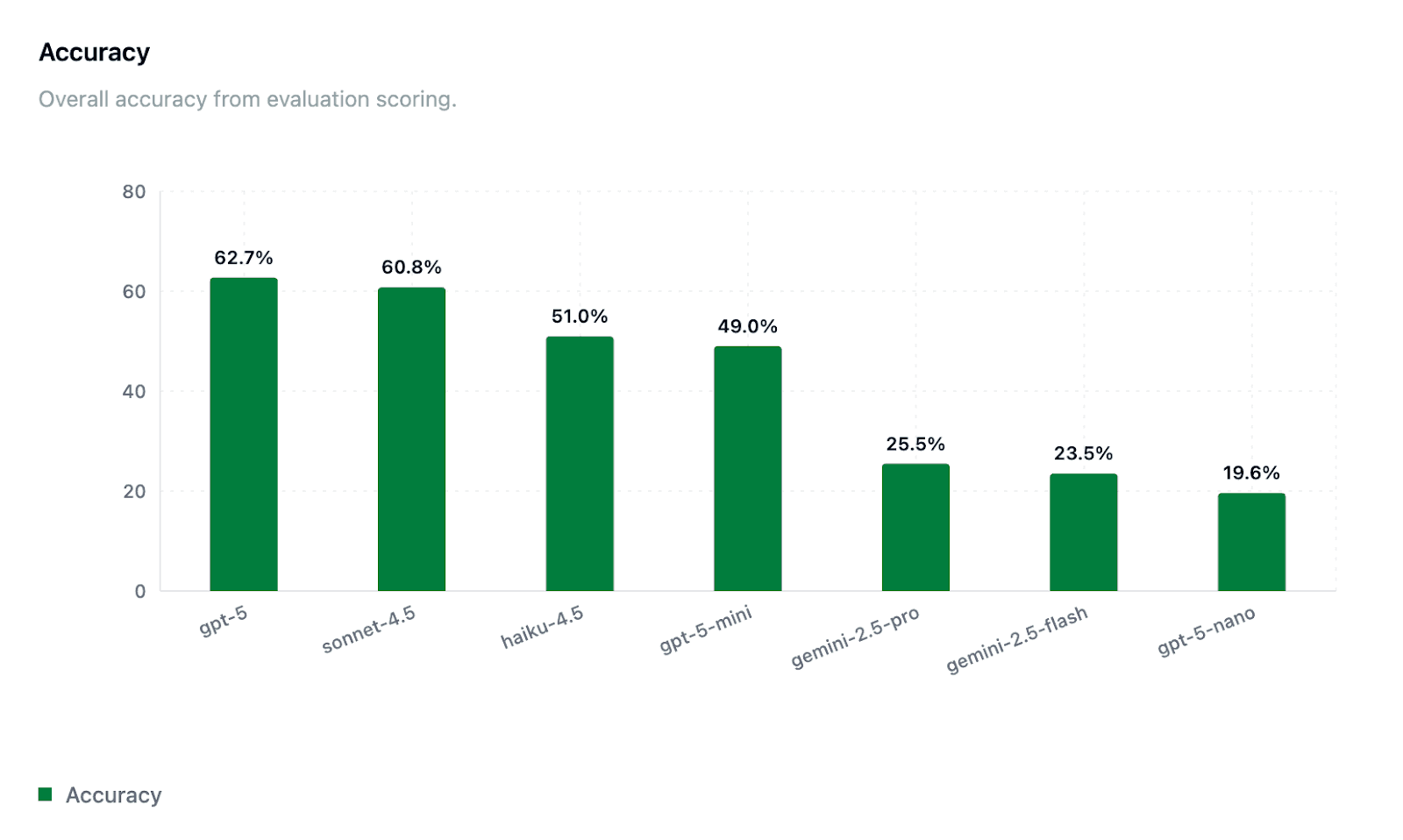
GPT-5 achieved the highest overall accuracy at 62.7%, closely followed by Claude Sonnet-4.5 (60.8%) and Haiku-4.5 (51.0%). Smaller OpenAI models such as GPT-5-mini (49.0%) and GPT-5-nano (19.6%) showed diminishing returns in accuracy with reduced cost.
Surprisingly (to us), Gemini-2.5-pro underperformed greatly on task accuracy. This is surprising because Gemini-2.5-pro regularly benchmarks well on many tasks, and is often competitive with the latest Sonnet & GPT models. We believe part of this underperformance could be attributed to the 12% task failure rate for the model (see Task Completion results below). We plan on diving deeper into debugging why this model failed to meet expectations on this task and environment and will publish our findings in a later post.
Cost Efficiency:
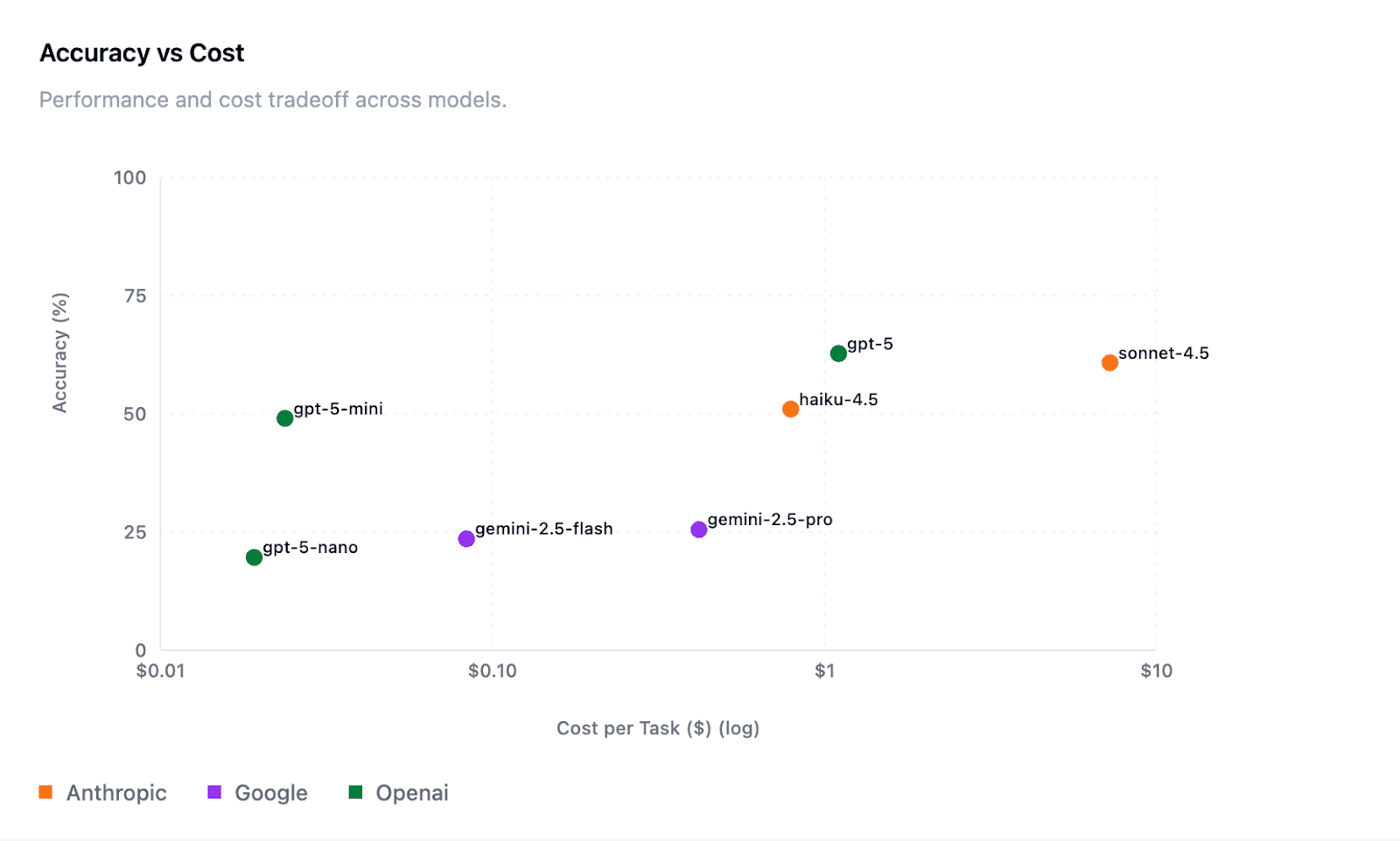
GPT-5 variants defined the performance-cost Pareto frontier, offering the best tradeoff between performance and dollar cost. Anthropic’s models were more expensive, with Sonnet-4.5 costing roughly 7x more per sample than GPT-5 for similar performance. Haiku-4.5 showed notable cost efficiency as well.
(Note: cost estimates exclude prompt caching)
Task Completion Rate:
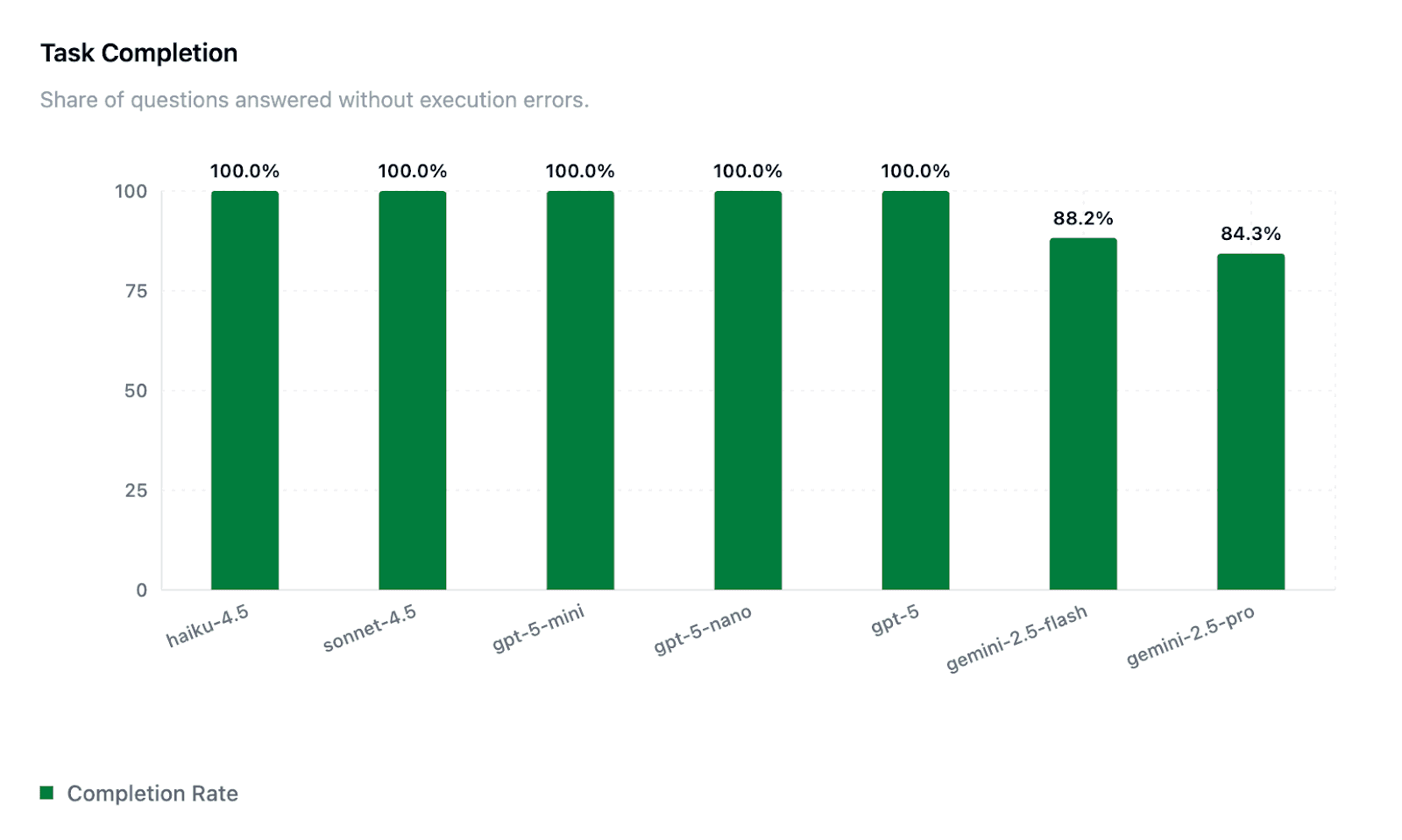
All OpenAI and Anthropic models completed every question successfully (100%), while Google’s Gemini models encountered some unrecoverable errors (84–88%). We intend to publish a follow up post with deeper analysis on these failures soon.
Task Duration:
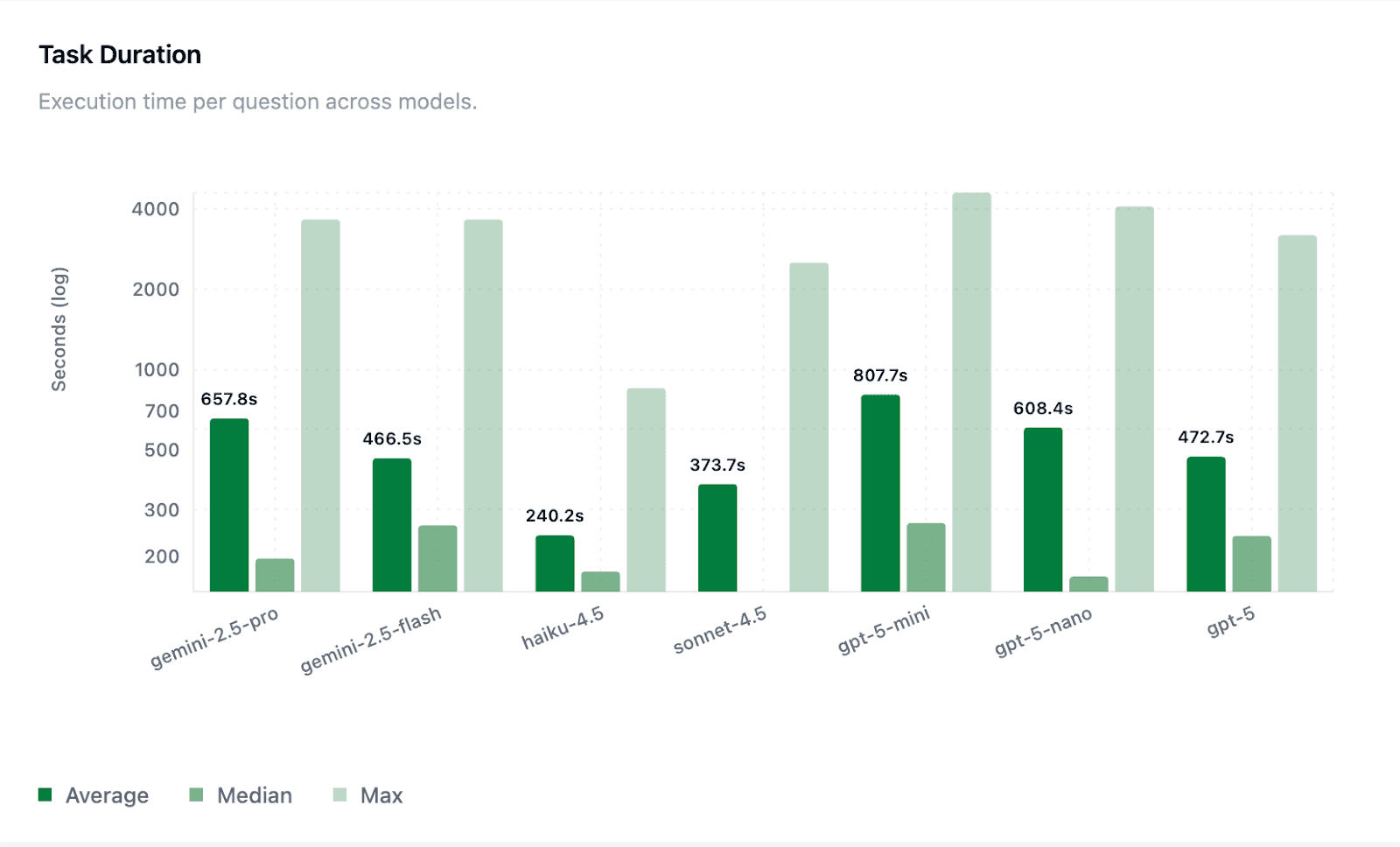
As expected, smaller models (or rather cheaper models, since model sizes aren’t disclosed publically) typically had lower request latency and general wall-clock task duration than their larger model family counterparts, but Claude Haiku-4.5’s combination of speed and accuracy stood out. Claude Haiku-4.5 completed tasks the fastest (~240s average). It interestingly achieved this while clocking in with the most tool calls per run (see Tool Efficiency section below).
GPT-5 averaged ~470s, which was interestingly lower than the smaller GPT-5-mini and GPT-5-nano (~807s and ~608s, respectively). This is worth a closer look to understand why this is the case generally, but our current hypothesis is that outlier long running task runs impact the average and that median task duration is important to pay attention to.It’s worth noting that we observed agents running for over 60 minutes while staying on track and producing an answer. This remains another avenue for deeper analysis that we save for a later blog post.
Tool Efficiency:
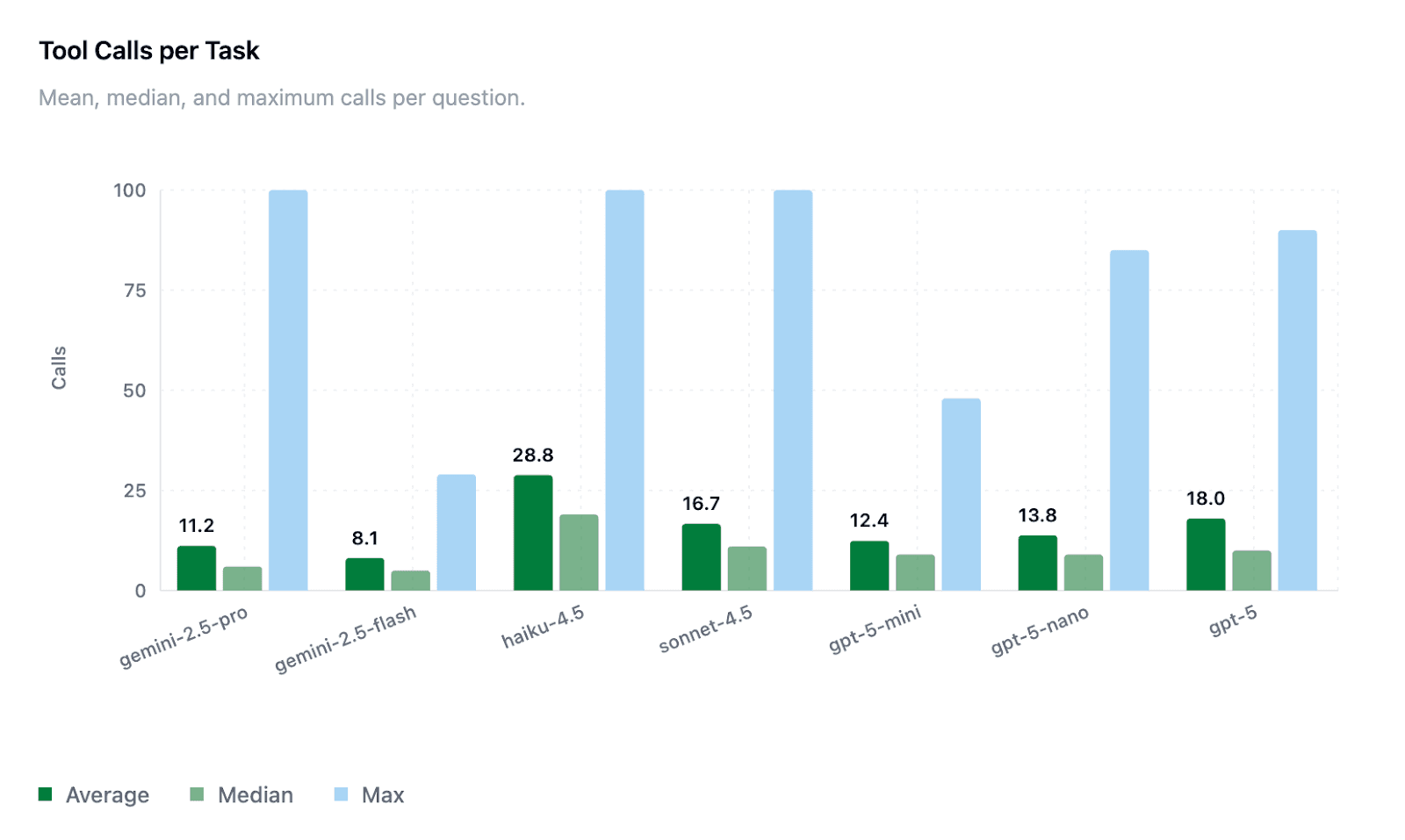
The number of tool calls per task is one of several measures of task efficiency. Haiku-4.5 averaged ~29 calls, while GPT-5 averaged ~18, showing a good balance of exploration and precision.
Max tool calls for some models reached 100 (indicating task timeouts - see Methodology section below), especially for Gemini variants. GPT-5 models showed more consistent call behavior (lower variance between median and max), suggesting better stability.
Token Efficiency:
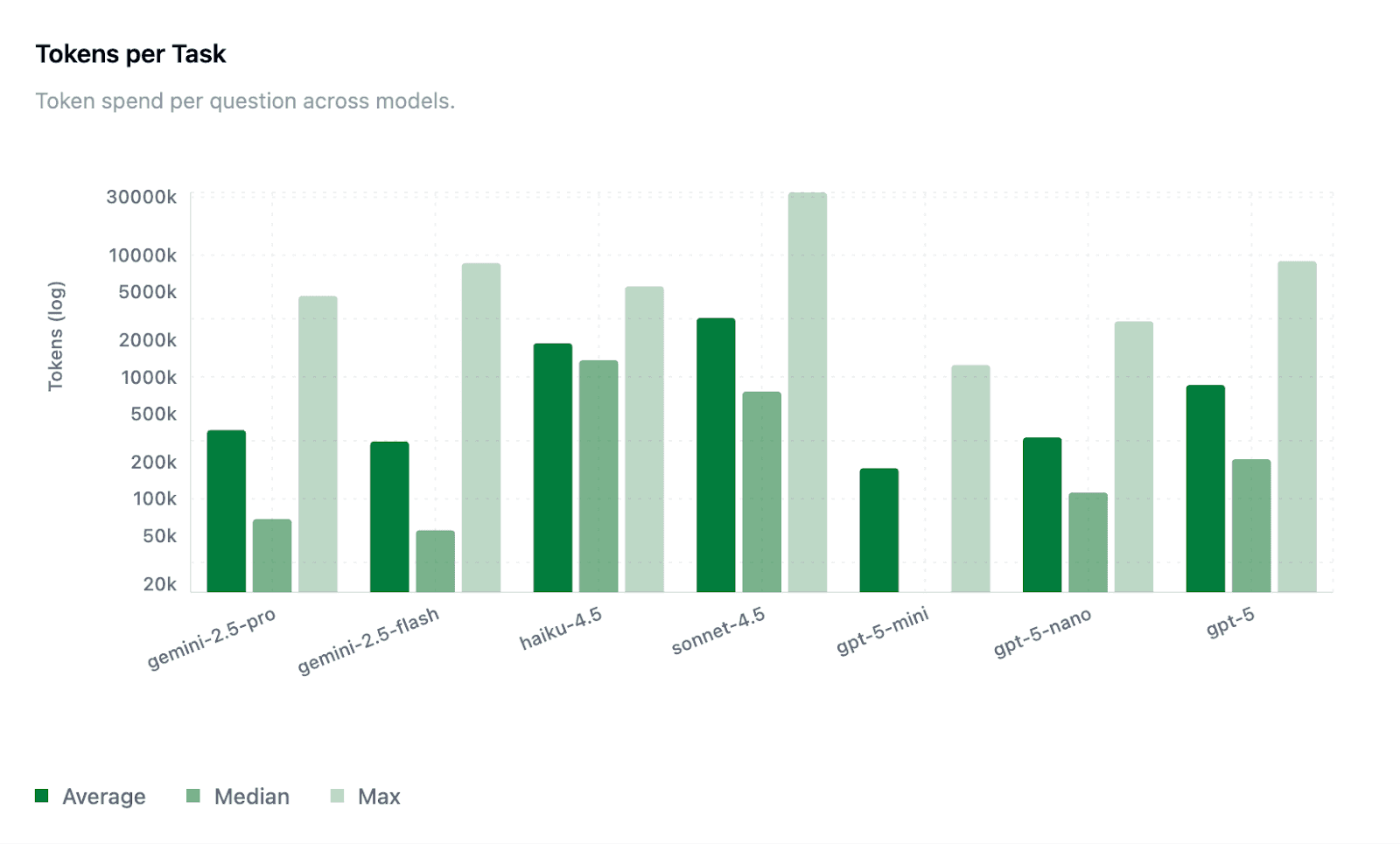
Average token usage varied greatly by model and provider, with larger models typically using more tokens to complete the task. Token usage is the sum of all input + output tokens over all agent loop turns.
Sonnet-4.5 and Haiku-4.5 had the highest average token usage (~3.3M and 1.7M respectively)
GPT-5-mini and GPT-5-nano consumed fewer tokens per task than GPT-5
Gemini 2.5 model family showed moderate token efficiency but large variance (max token spikes)
Interpretation for Security Teams
For real-world SecOps agents:
GPT-5 is the most cost efficient high performing model for blue team investigations
Haiku-4.5 is ideal for interactive triage or real-time alert enrichment where response time matters.
GPT-5-mini can serve cost-sensitive continuous tasks like log summarization or pattern analysis where task duration is not a priority.
Gemini models may be suitable for lightweight classification tasks but currently lag behind in accuracy and tool reliability.
We expect these patterns to hold across other SecOps tasks and plan to validate this with expanded evaluations across different tool stacks and security workflows (see Further Work section below).
Methodology
A few additional high level points on how we approached this eval:
We provided the same minimal system prompt to all models for all questions
We did not tune or iterate the prompt for any particular model nor in response to any error analysis
You are a cybersecurity analyst investigating a security incident using Splunk. You have access to the splunk_search tool to query data.
Your goal is to answer questions accurately using the available Splunk data. Follow these guidelines:
Use the splunk_search tool to run SPL queries and explore the data
Analyze the results carefully to find the answer
If you need more information, run additional queries
Provide only the final answer in your last message according to any provided answer guidance (Example: If the answer is a hostname, IP address, username, or other identifier, provide it exactly as requested)
Periodically reflect on your progress and adjust your strategy accordingly as you iterate through the queries and logs
If you cannot find the answer after thorough investigation, do not guess, state "Unable to determine" and explain why
Remember: The goal is to find the correct answer using Splunk queries. Be thorough but efficient.
Some BOTSv3 questions were modified slightly
Some questions build context upon each other because they were designed to be answered sequentially by a human in a CTF challenge setting. That meant some questions referred to the answers of previous questions implicitly. Since LLMs have no native memory, we include any relevant implied context to questions that a human would have possessed. We feel this was acceptable and does not give the Agent any advantage.
BEFORE
Bud accidentally commits AWS access keys to an external code repository. Shortly after, he receives a notification from AWS that the account had been compromised. What is the support case ID that Amazon opens on his behalf?
AWS access keys consist of two parts: an access key ID (e.g., AKIAIOSFODNN7EXAMPLE) and a secret access key (e.g., wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY). What is the secret access key of the key that was leaked to the external code repository?
Using the leaked key, the adversary makes an unauthorized attempt to create a key for a specific resource. What is the name of that resource? Answer guidance: One word.
AFTER
Bud accidentally commits AWS access keys to an external code repository. Shortly after, he receives a notification from AWS that the account had been compromised. What is the support case ID that Amazon opens on his behalf?
AWS access keys consist of two parts: an access key ID (e.g., AKIAIOSFODNN7EXAMPLE) and a secret access key (e.g., wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY). Bud committed AWS access keys to an external code repository and AWS opened support case ID 5244329601 on his behalf. What is the secret access key of the key that was leaked to the external code repository?
An adversary used a leaked AWS access key (secret key: Bx8/gTsYC98T0oWiFhpmdROqhELPtXJSR9vFPNGk) to make unauthorized attempts. The adversary makes an unauthorized attempt to create a key for a specific resource. What is the name of that resource? Answer guidance: One word.
We also remove questions that require web search or browser access. Cotool has access to both these classes of tools, however we wanted to downscope the evaluation to start (we plan to evaluate with these tools very soon!)
Example of question removed:
According to Symantec's website, what is the severity of this specific coin miner threat?
We evaluate correctness for the “accuracy” metric as a case-insensitive exact string match against the ground truth answer
We use “thinking” versions of all models where applicable
We limit Agent loops to 100 iterations, at which point we remove access to tools to force an answer
Cotool’s Agent harness includes specialized Splunk tool implementations that assist in effective tool calling. Nothing about this implementation was specialized or changed for the BOTSv3 data or this eval
With respect to the metrics reported above, we leverage prompt caching for all providers. This will inherently make task duration lower than it would be otherwise. Prompt caching also dramatically reduces the effective cost per task due to the high cache utilization in Agent loops.
Other Notes
We’ve found evidence of BOTSv3 data being discussed in detail on the internet, so there is a high probability of train / test data contamination in the pretraining of frontier models. We haven’t seen any evidence of answer memorization but are interested in validating this more robustly, especially for larger models.
Future Work
This initial BOTSv3 benchmark represents only the foundation of Cotool’s evaluation framework. Our goal is to evolve this into a comprehensive and continuously updating system that measures how AI agents perform across the full range of security operations tasks.
Follow-up Analysis
We have some unanswered questions from the eval that we’d like to get to the bottom of:
Deeper investigation into why Gemini-2.5-pro underperformed, including debugging its high task-failure rate.
Detailed analysis of Gemini models’ unrecoverable errors, as mentioned in the Task Completion section.
Exploration of why GPT-5 sometimes runs faster than GPT-5-mini/GPT-5-nano, including studying outlier long-running tasks and median vs. mean duration.
Analysis of extremely long-running agent trajectories (agents that stayed on track for 60+ minutes)
Expanding Scope
We plan to extend the eval harness beyond Splunk to include multi-tool environments. This means agents will soon be tested against data from cloud telemetry sources (AWS CloudTrail, Azure Sentinel, GCP SCC), identity providers (Okta, Microsoft Entra, Google Workspace), and endpoint or CSPM platforms (CrowdStrike, Wiz, Orca). These integrations will allows us to run full investigative tasks correlating identity, cloud, and endpoint data in a single evaluation.
Continuous Evaluation
We are also developing the infrastructure for continuous evaluation. Cotool agents will automatically re-run benchmark suites whenever a new model version is released, a connector schema changes, or a new detection rule is synced. The long-term vision is a live, continuously updated performance telemetry system. Our goal over time is to approach software CI/CD pipelines but for agent quality and reasoning reliability.
Optimization Experiments
With a stable harness in place, we will begin running controlled experiments to understand what drives performance. This includes prompt ablations, tool-calling heuristic tests, and reinforcement learning research to improve reasoning efficiency and accuracy. These studies will help separate what’s model-driven from what’s system-design-driven in overall agent capability.
Call For Participation
Evals in security operations are an evergreen challenge. As agents take over more security operations tasks, benchmarking performance becomes increasingly critical. Our goal is to push the community forward with better metrics so that security teams can properly understand agent capabilities before handing over mission-critical tasks. This includes exploring where releasing open source projects would be beneficial.
If you are:
Participating in or building blue-team CTF challenges or security training scenarios
Working with production security datasets that could be anonymized for benchmarking
Researching agent evaluation methodologies or prompt optimization techniques
Running a security operations team interested in testing agents in controlled environments
Building security-specific agents at your company and have insights on model effectiveness for different tasks
We'd love to hear from you. Reach out at eddie@cotool.ai or on X: @cotoolai

